Member-only story
Squeeze Every Drop of Performance from Your LLM with AWQ (Activation-Aware Quantization)
A Guide to Quantize LLMs Using AWQ on a Google Colab Notebook
Ever Wondered how to quantize LLMs? Here is a comprehensive guide to Quantize LLMs using AWQ. GGUF Quantization Blog will be out soon
Introduction
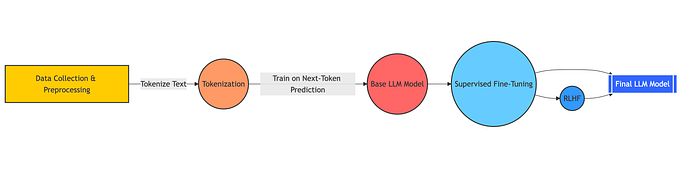
Large language models (LLMs) like GPT-3, PaLM, and LLaMA have proven tremendously powerful. But their hundreds of billions of parameters also make them incredibly computationally demanding. To deploy these models in production, we need ways to make them more efficient.
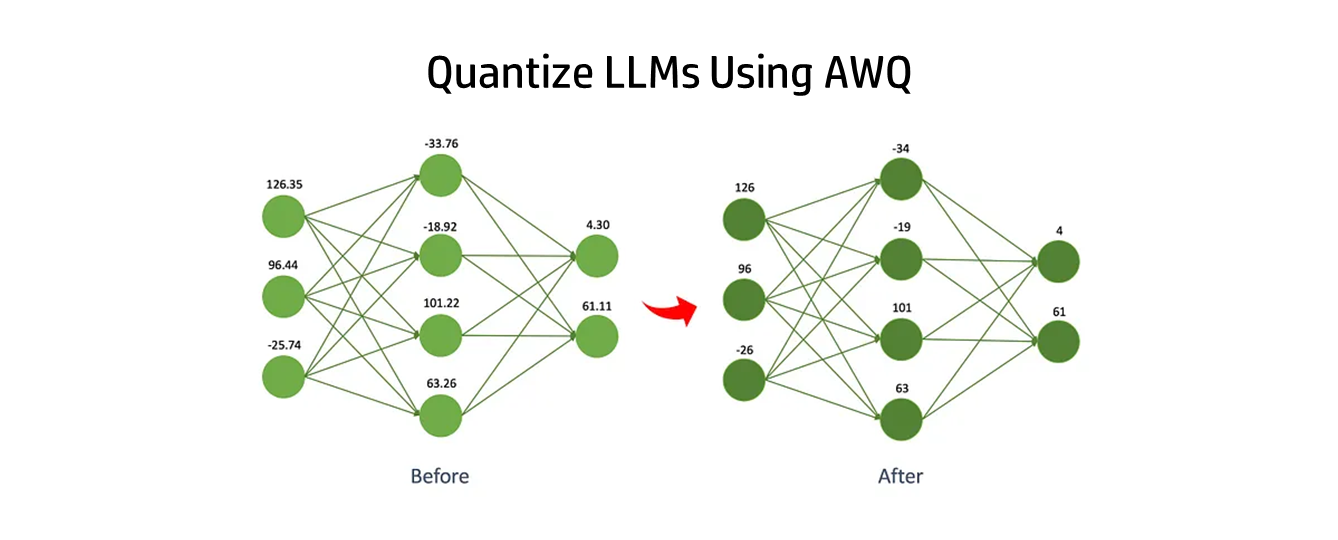
This is where quantization comes in. By reducing the precision of weights in a neural network from float32 to lower bitwidths like INT8, INT4, or even INT2, we can shrink the model size and significantly speed up computation. However, naive quantization that simply rounds weights to lower precision can seriously hurt model accuracy. We need smarter quantization techniques optimized specifically for large language models.
Enter Activation-Aware Weight Quantization (AWQ) — a method tailored for quantizing LLMs with minimal impact on accuracy. In this post, we’ll dive into what AWQ is, how to use it, and the performance benefits you can realize.